Why your JavaScript content can show up in Google days after you publish it.
Google reads your page twice. The first read happens when Googlebot fetches the raw HTML your server returns. The second read happens later, after a headless Chromium executes your JavaScript and produces the final DOM. Anything that only exists after JavaScript runs, body copy, internal links, structured data, your canonical tag, waits for that second read before Google can use it.
That second read is not instant. Google's own JavaScript SEO documentation describes a render queue and says a page "may stay on this queue for a few seconds, but it can take longer than that." For a server-rendered page that gap does not matter, because everything was already in the first read. For a client-rendered page it is the whole ballgame. This is the mechanism behind the pattern teams keep reporting and rarely diagnose correctly. New content that takes days to rank. Internal links that Google seems slow to follow. Structured data that validates in the testing tool but never earns a rich result.
The three phases, and where the queue sits
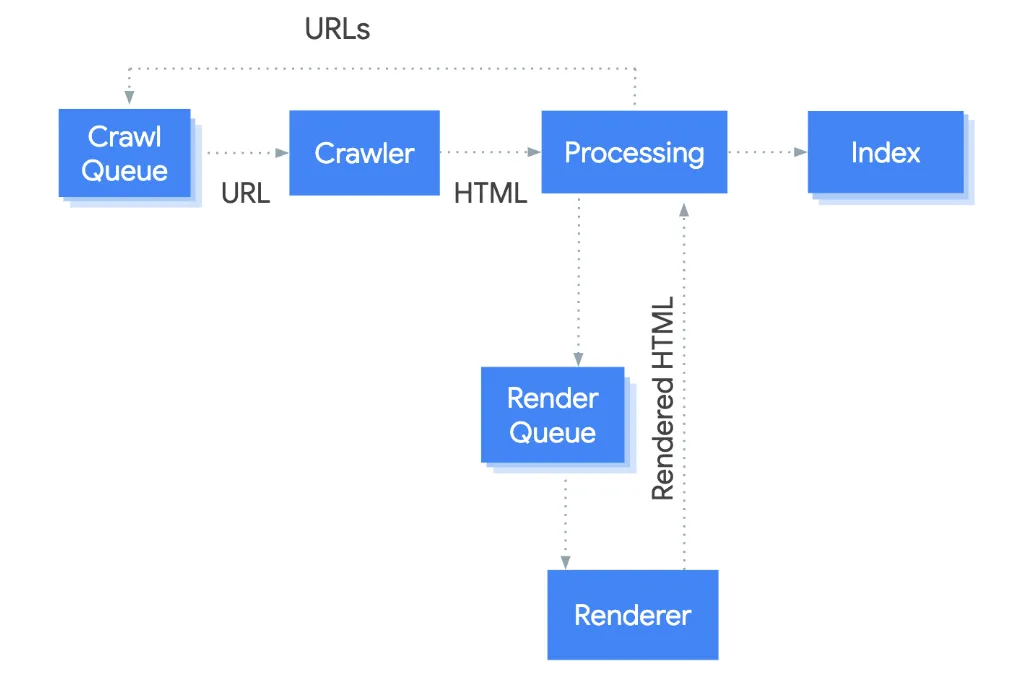
Google processes a page in three phases that the documentation lays out plainly. Crawling, then rendering, then indexing. Googlebot pulls a URL from the crawl queue, makes the HTTP request, and parses the returned HTML. It extracts the links it finds in href attributes and pushes those back onto the crawl queue. Then, per Google, it "queues all pages with a 200 HTTP status code for rendering, unless a robots meta tag or header tells Google not to index the page."
Read that line carefully. Every 200 page goes to the render queue, JavaScript or not. Rendering is no longer a special path reserved for heavy single-page apps. Google's Martin Splitt has said the two-waves model matters less and less because rendering turned out to be cheap, so Google runs nearly everything through it. The headless Chromium loads the page, executes the script, and hands the rendered HTML back to be parsed a second time, for links and for content. The rendered output is what gets indexed.
So there are two queues, not one. A crawl queue and a render queue. A page can clear the first and sit in the second. The documentation is explicit that it is "not immediately obvious when a page is waiting for crawling and when it is waiting for rendering," which is exactly why this is hard to diagnose from the outside.
How long is the wait, really
The honest answer is shorter than the scare stories and longer than zero. Google has described a median rendering delay measured in seconds, around five, for healthy pages. Splitt's framing is that rendering is cheap enough that Google stopped rationing it the way it once did. If you publish a server-rendered page on a healthy site, the rendered version often follows within minutes.
The lag bites in specific conditions. Large sites with millions of URLs, sites with weak crawl demand, pages stuffed with slow third-party scripts, and pages where the rendered output keeps changing all push render further back in line. Independent analysis by Onely found Google needed roughly nine times longer to get JavaScript content through the pipeline than plain HTML in their test set. Whether your number is five seconds or five days depends on your render budget, which is a separate constraint from crawl budget. Crawl budget is how many URLs Google is willing to fetch from you. Render budget is how much headless-Chromium compute it is willing to spend executing your scripts. A page can be cheap to crawl and expensive to render, and the render cost is the one that delays JavaScript content.
What actually goes missing at the first read
The first read sees only what your server put in the HTTP response. On a client-rendered page that response is often an app shell, a near-empty skeleton that Google's docs describe as containing none of the actual content. Until rendering completes, here is what Google does not have.
Body content. If your article text is injected by JavaScript, the first read indexes an empty page. Google may index that thin version first and update it after rendering, which means a window where you rank for nothing.
Internal links. This is the expensive failure nobody watches for. Google discovers new URLs by parsing links out of HTML. If your navigation and in-body links only exist after JavaScript runs, then link discovery waits for rendering too. Render lag on a hub page becomes crawl lag on every page it links to. Your freshest articles wait in line behind the render queue of the page that points to them.
Structured data. JSON-LD injected by JavaScript is only seen after rendering. It will pass the Rich Results Test, which renders the page, while still being slow to earn the actual rich result in live search.
The canonical tag and the title. Google supports setting these with JavaScript but warns against it, and for canonicals specifically tells you to never use JavaScript to change the canonical to a different value than the one in the original HTML. A JS-injected canonical is read at render time, which is later and less reliable than putting it in the served HTML.
Diagnosing render lag in Search Console
You do not need a log pipeline to see this. The GSC URL Inspection tool gives you both reads, and the trick is to compare them.
Run URL Inspection on a published page, then open Test Live URL and look at the rendered HTML under View Tested Page. That is the second read, the rendered DOM as Google's headless Chromium produced it. Now open the page's raw HTML separately with view-source in your browser, which is roughly what the first read sees. Diff the two. Text, links, or structured data that appear in the rendered HTML but not in view-source are content that depends on rendering, which means they depend on the render queue. The more of your important content sits in that gap, the more exposed you are to indexing lag.
There is a second comparison worth running. The "View Crawled Page" version in URL Inspection shows the last indexed snapshot, which can be days or weeks old. If the crawled snapshot is missing content that your live test renders fine, you are looking directly at render lag in production, not a hypothetical. Treat the live test as ground truth for capability and the crawled snapshot as evidence of timing.
One caution from Google's docs that catches people. When Google sees a noindex tag, it "may skip rendering and JavaScript execution." So if your noindex is itself injected by JavaScript, the logic can fold in on itself. Put indexing directives in the served HTML.
The JavaScript patterns that trigger the worst lag
Not all client-side code is equal. A few patterns reliably push content into the render-dependent gap.
Routing with URL fragments. Google's documentation is blunt that it cannot reliably resolve fragment routes like #/products, and tells you to use the History API with real href URLs instead. Fragment routing hides your entire link graph behind rendering, and sometimes behind nothing Google can follow at all.
Content that loads on interaction. Googlebot does not click, hover, or scroll. It renders the page at a tall viewport and indexes what is present, but it does not fire scroll events to trigger your lazy-loaders. Content gated behind a scroll listener or a "load more" click can stay invisible. Google maintains a separate guide for making lazy-loaded content visible to Search precisely because the naive implementations fail.
Stale cached scripts. Google's WRS caches resources aggressively and, per the docs, "may ignore caching headers," which can leave it running an outdated version of your JavaScript or CSS. The fix Google names is content fingerprinting, filenames like main.2bb85551.js whose hash changes when the file changes, so an update always forces a fresh fetch. Ship code under non-fingerprinted filenames and you risk Google rendering your new page with your old bundle.
Heavy third-party scripts in the critical path. Every script the renderer has to execute adds render cost, and render cost is what delays the second read. Scripts that block content from appearing in the rendered DOM are the ones that hurt indexing, not just user experience.
What to actually do about it
The durable fix is to stop making your important content render-dependent in the first place. Server-side rendering or prerendering puts body copy, links, structured data, titles, and canonicals into the first read, where Google can use them immediately. Google still recommends this directly, noting it makes the site faster for users and crawlers and that not all bots run JavaScript at all, which matters more every quarter as AI crawlers that skip rendering pull from your raw HTML.
If you cannot move everything server-side, prioritize. Get the things link discovery and ranking depend on into the served HTML. Real <a href> links so your graph is crawlable without rendering. The canonical tag and robots directives in the HTML head. The article's main text where possible. Leave the genuinely interactive, post-load enhancements to client-side code, since those are the parts where render timing does not cost you indexation.
Then verify with the diff above. Render parity between your raw HTML and your rendered HTML for the content that matters is the goal. When the gap is empty of anything important, the render queue stops being your problem and goes back to being Google's.
If new pages on your site are slow to index or your structured data never quite lands, a rendered-versus-raw audit usually finds why. Our free AI Visibility Audit looks at how AI assistants and search engines actually see your pages, and render parity is part of the technical review behind it. Talk to us if you want eyes on where your content is hiding behind JavaScript.
See where your brand stands in AI answers today, benchmarked against your competitors, no pitch required.

Most of what AI cites about your brand lives on sites you do not control
The first Total Graph Authority post named third-party validation as the layer AI cites most. This is the deep dive, six trust tiers, engine by engine, in the order to build them.
read_post →
The five graphs an AI assistant reads before it decides to cite you
Backlinks are one connection an AI model follows. Here are the other four graphs that decide whether you get named in the answer.
read_post →
What AI knows about your brand is decided first on your own domain
Third-party mentions and social clips only corroborate a story your own site has to tell first. Here is how to build the first-party layer AI reads before it trusts anyone else.
read_post →