What a Senior SEO Found When He Read Our Source Code.

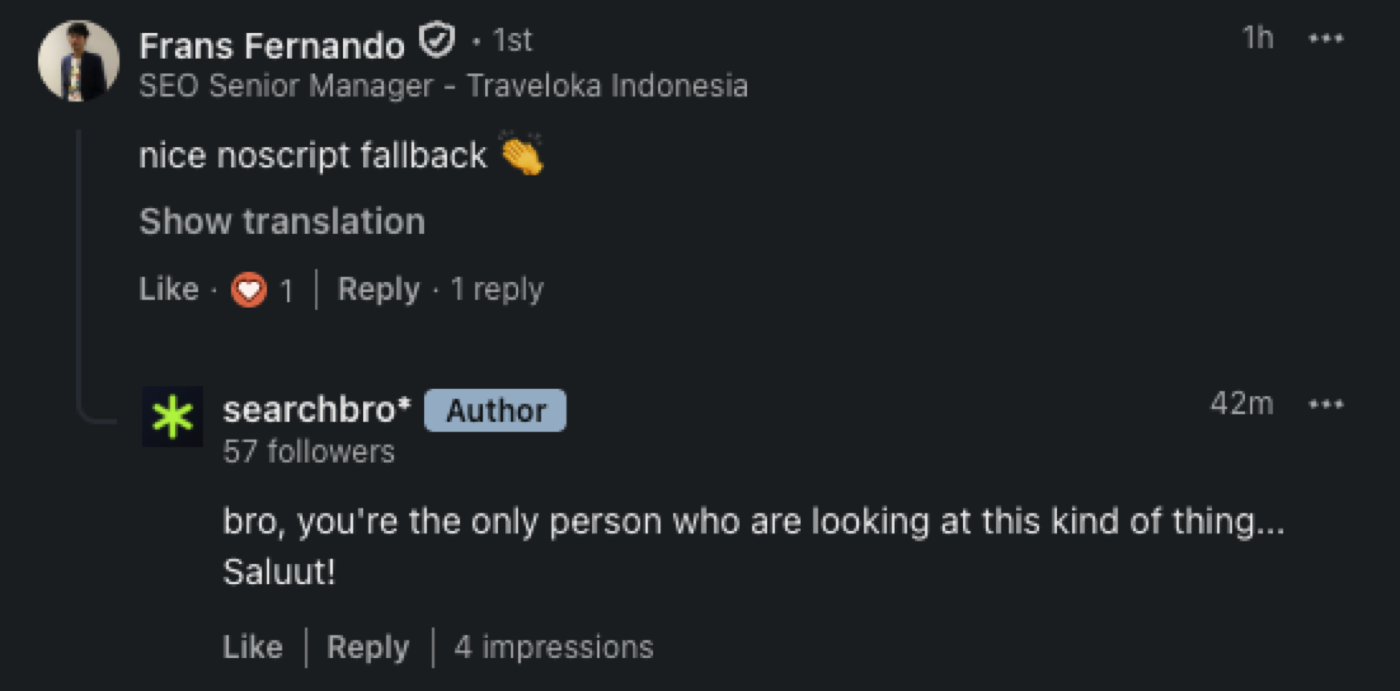
A senior SEO manager at one of Indonesia's biggest tech companies opened searchbro.id, went to his own profile, and did the thing only an SEO does for fun. He viewed the page source. Then he left an approving note about the noscript fallback. For most people that sentence is gibberish. For anyone who has shipped a JavaScript site and watched it disappear from search, it is the whole story.
searchbro.id, our living index of Indonesia's search specialists, is a JavaScript application. The rotating 3D sphere on the homepage, the profile cards, the filters, all of it gets drawn by a script after the page loads. That design choice carries a risk, and the SEO reading our source knew exactly which one.
The blank page most crawlers see
A JavaScript-heavy site has a failure mode you cannot spot in a browser. The content is not in the HTML the server sends. It only appears after the browser downloads the script, runs it, and assembles the page in memory. A person on a modern browser never notices. Anything that does not execute JavaScript receives an empty shell.
That category is larger than most teams assume: social scrapers building link previews, accessibility tools, browsers with scripting turned off, and the readers that now matter most, AI crawlers. Vercel and MERJ tracked more than 500 million fetches from OpenAI's GPTBot and found no evidence of JavaScript execution at all. The bot downloaded script files about 11.5% of the time and never ran them (Vercel). GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, and Meta's crawler all work this way. Google's Gemini is the rare exception, since it borrows Googlebot's rendering. The rest take the raw HTML and move on.
A client-rendered site can look flawless to you and your customers while showing up as nothing to the systems now choosing which brands to name in an answer.
What we built into searchbro
The fix predates AI search by years, and it still holds. We ship the real content as static HTML and let the JavaScript app load on top of it for the people who can run it.
A build step called build-seo.mjs prerenders one static HTML file for every route on the site: each specialist, each city hub, each Space post. Two things go into every one of those files.
First, a complete `<head>`: title, meta description, Open Graph tags for social previews, a canonical URL, and JSON-LD structured data. We mark up people as `Person`, the index pages as `CollectionPage`, and the community posts as `DiscussionForumPosting`, so a machine knows what each page is before it reads a single line of body copy.
Second, a `<noscript>` block carrying the actual content: the heading, the person's role and company, their photo, the full bio, the links. Browsers running JavaScript skip that block and load the interactive app instead. A crawler that cannot run JavaScript has nothing else to read, so that block becomes the page it indexes.
Because the content lives inside the static file, a crawler that never runs the script still receives the whole page in one fetch. Firebase serves those prerendered files straight to bots as fully formed HTML. The visitor whose browser can run the script still gets the 3D sphere loaded on top.
The split that decides everything is whether a reader runs JavaScript. A person on a current browser gets the full app, and Googlebot gets there too after its rendering delay. Everyone else is where a client-rendered site loses. GPTBot, ClaudeBot, and PerplexityBot land on an empty shell and index nothing, and social preview scrapers and accessibility tools hit the same wall. On searchbro, all of those readers receive the prerendered HTML and structured data in the first response, because none of it was ever locked behind a script.
Why an old technique is the right one for AI search
It is tempting to treat AI visibility as a new discipline with new rules. Most of the time it rewards the fundamentals classic SEO always rewarded, pointed at a new reader. A crawler that cannot render JavaScript in 2026 has the same need Googlebot had a decade ago: content present in the HTML, marked up clearly, served fast. Build for that and you serve the search engine and the answer engine in the same stroke.
This is why a senior practitioner recognizing the technique counts for more than a compliment. He inspected the plumbing of a site built by people who claim to understand search, and the plumbing held. Frans Fernando, a senior SEO manager at Traveloka, left the note after reading the source of his own profile, which is the kind of audience searchbro was built to earn.
How to check your own site

You do not need our build to find out where you stand. Three steps, ten minutes:
Turn JavaScript off in your browser through DevTools, then reload a page that matters. What is left on screen is close to what a non-rendering AI crawler sees. A blank or skeletal page is the warning.
Use View Source, not Inspect. The Inspect panel shows the rendered DOM, which papers over the problem. View Source shows the raw HTML the crawler actually receives.
Search that raw HTML for your real body content and your structured data. An empty body and missing JSON-LD mean your pages are invisible to most of the systems now sending buyers your way.
When the page comes back blank, the answer is prerendering or server-side rendering with a real content fallback, the same pattern running underneath searchbro.
This is the unglamorous layer beneath "AI-ready content." A brilliant content strategy reaches nothing if the crawler reads an empty page first. Our AI Search Optimization work begins by making sure your pages are legible to the crawlers feeding ChatGPT, Gemini, and Perplexity. Talk to us and we will show you exactly what the bots see when they reach your site.
See where your brand stands in AI answers today, benchmarked against your competitors, no pitch required.

Your content can sit inside two billion AI answers a month and still send zero visitors
Your content can be quoted inside two billion AI answers a month and still send zero visitors. That is not a traffic problem, it is a measurement problem, and the old dashboard cannot see it.
read_post →
How to build video that AI search actually cites
YouTube is the most-cited source in Google's AI Overviews, and short-form is where product discovery now begins. What it takes to make your videos the ones AI search pulls from.
read_post →
Google turned every search into an AI answer first
Google rolled Gemini out as the default answer on every query worldwide, and the blue links slid below the fold. Here is what actually changed, and how to keep earning traffic when the answer arrives before the click.
read_post →