Schema Markup That Still Moves the Needle in 2026.
A schema audit in 2026 should start by deleting code, not adding it. Most enterprise sites still ship structured data that no surface renders, no engine rewards, and no team has reviewed since the JSON-LD was pasted in. The interesting question is not which schema to add this quarter. It is which schema is actually earning a result somewhere, and which is sitting in your `<head>` for no reason at all.
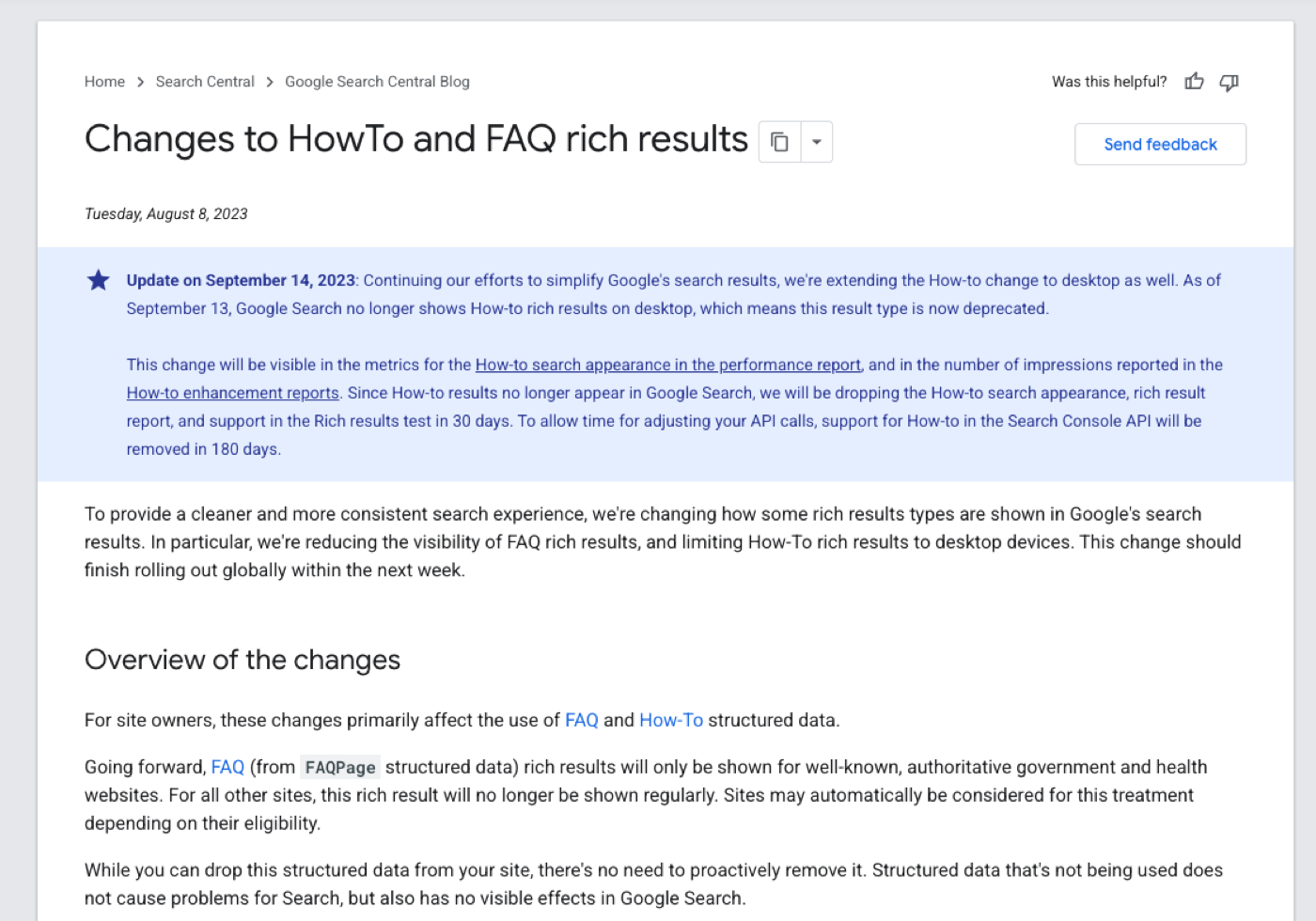
The deletion case got sharper three weeks ago. On May 7, 2026, Google's developer documentation grew a deprecation banner: FAQ rich results were no longer being shown in Search, with the rich result test losing support in June and the Search Console API losing it in August. That follows the August 2023 deprecation of HowTo rich results, which has been a tombstone in most sites' schema for nearly three years. If your CMS is still emitting FAQPage or HowTo blocks, the only question is whether the cost of keeping them is more than the cost of cleaning them out. There is no upside.
That deletion job is the first move in a schema strategy that still pays in 2026. The second move is rebuilding the case for the schema types that do.
What schema is actually for now
Before deciding what to ship, it is worth being honest about what structured data does and does not do. John Mueller has been clear for years that schema is not a generic ranking factor; in his framing it is "an extremely light signal" that helps Google understand what a page is about. That phrasing irritates teams who want a bigger lever, but it is exactly the right framing for prioritization. Schema does three jobs in 2026, and only three.
It earns specific rendered features in the SERP, like product cards, review stars, breadcrumb trails, recipe carousels, video previews, and event listings. These features still drive measurable click-through differences when they appear. The list of what Google will actually render is in the Search Gallery, and it is shorter than most agency decks suggest.
It declares entities and relationships in a form that the knowledge graph, the Bing entity index, and AI retrieval pipelines can consume without having to guess. Organization, Person, Product, Service, and LocalBusiness markup is the cheapest way to make explicit what your unstructured copy is implying. AI search engines that have confirmed schema use, including Google AI Mode and Bing Copilot, lean on this layer.
It future-proofs the page against rich features Google has not built yet. Martin Splitt's standing answer when teams ask why they should mark up things that do not currently render is that schema shipped today is the foundation Google uses to ship features tomorrow. A weak short-term argument, a strong long-term one.
Anything outside those three jobs is decoration. The deletion list mostly lives there.
The schema worth shipping, ranked by ROI
For an enterprise site in 2026, the schema budget should concentrate on a small number of types where the result is visible, the implementation is maintainable, and the alignment with AI extraction is meaningful. The honest ranking, ordered by the return we see in enterprise audits, looks something like this.
Product and Offer schema, on every commercial page that has a price. The single highest-ROI schema type on the web, and the cost of getting it wrong is also the highest, which is why it deserves dedicated QA. Display price, currency, availability, GTIN, brand, AggregateRating, and individual Reviews when you genuinely host them. For multi-variant products, mark up the variants. The rich product card directly affects CTR, and the same markup feeds Universal Cart, the shopping graph, and the way AI assistants compare products inside conversational queries.
Organization schema on the homepage, with logo, sameAs links to verified social and professional profiles, founder if appropriate, and address if the brand has one. This is the entity declaration that anchors everything else and the cheapest way to influence what knowledge panels, AI summaries, and brand SERPs say about the company. Most enterprise sites have a stale Organization block written in 2019. Refreshing it is one sprint that returns disproportionately.
LocalBusiness schema for multi-location operations, one block per location page, properly nested and unique. One of the few schema types that demonstrably influences local pack inclusion and Google Business Profile matching. For Indonesian brands running multi-city footprints, this is non-optional; we have argued the same in our local SEO work.
Article schema on editorial and news, with headline, author, datePublished, dateModified, publisher, and a proper image. The rendered carousel is variable. The entity signal is not. AI engines that cite editorial content lean heavily on the author and publisher fields to assess trustworthiness, and many sites still leave the author field as a string rather than a properly nested Person entity with sameAs links.
BreadcrumbList schema, on any page with a non-trivial hierarchy. The render is small but consistent, and the structural signal it gives Google about site architecture is worth more than the visual.
Video schema, on pages with native video. Most enterprise teams own video assets that are never marked up, never appear in the video carousel, never carry a duration in the SERP, and never surface inside Bing Copilot's video previews. The fix is cheap.
Course and Event schema, where they apply. Both still render reliably, both feed knowledge graph queries, both are underused by competitors.
Review and AggregateRating, only when you genuinely host structured reviews. Google has been aggressive about demoting fake or inflated review markup. Mark up what you really publish, nothing else.
What to retire from the codebase
The flip side is the retirement list. FAQPage in any form intended for the rich result is dead; Google will keep parsing it for content understanding, but the time spent crafting question-answer pairs to game the SERP module has zero return. HowTo is dead and has been since 2023. Sitelinks Search Box is no longer rendered. DataFeed and any custom Google-specific extensions that were never adopted by other engines should be cleaned out of the templates.
The harder conversation is with schema added on the theory that more is better. Multiple Organization blocks on the same page. WebSite schema with potentialAction declarations no engine has acted on in years. Speakable, always limited to news and barely used. The audit should mark these as out of scope, not as broken, and the cleanup ticket should sit with engineering rather than SEO.
How AI engines actually use structured data
The most overcooked claim of the past year is that schema is a magic switch for AI citations. It is not. The honest version, which Search Engine Land laid out in its piece on schema in AI search without the hype, is that AI engines parse structured data when it is present and use it to resolve ambiguity, attribute facts, and disambiguate entities. They do not preferentially cite pages because the JSON-LD is well-formed.
What this means in practice is concrete. When an AI engine extracts a fact from your page to support an answer, structured data raises the probability that the fact is attributed to your brand correctly rather than to a third party that happened to mention you. When the engine has to decide which of three competing pages is canonical for a given product, schema-declared entities help it choose. When it builds a knowledge graph entry for a person, organization, or product, the sameAs and identifier fields let it merge your data into the right node rather than spawning a duplicate.
None of that is a citation guarantee. All of it shifts the odds in your favor. Teams investing in AI search visibility should treat schema as table stakes, not as the strategy. The strategy is the content, the citations, and the entity footprint outside your own domain. Schema is the layer that makes those investments legible.
The audit, in five moves
The fastest way to bring a large site's schema into 2026 is a short sprint, not a quarterly project. Five moves, in order.
First, crawl the site with Screaming Frog or Sitebulb, export every structured data block by URL, and bucket by schema type. Most enterprises discover at least three schema types they did not know were being emitted.
Second, run the export against the Search Gallery list. Anything not on that list earns no rendered feature. That does not mean delete it, but it does mean justify it.
Third, validate every remaining type in the Rich Results Test and in Schema Markup Validator. Errors and warnings on commercial pages are emergencies, not backlog.
Fourth, mark the deletion candidates: FAQPage, HowTo, Sitelinks Search Box, anything duplicate or contradictory. Issue a single engineering ticket to remove them at the template level rather than page by page.
Fifth, mark the gaps: Product pages without Offer, location pages without LocalBusiness, articles without proper Person markup on the author. These become the build queue.
The whole audit, for a 50,000-URL site, is two weeks of work for a senior technical SEO and a half sprint of engineering time. Track the impact in Search Console's rich result reports and in your own analytics, ideally inside a measurement layer that connects schema changes to SERP feature appearance rather than treating them as independent events.
A working example
A multi-brand Indonesian retailer comes in with FAQPage on every category page (a 2022 decision to chase the rich result), HowTo on guide pages, Organization on the homepage but not the brand subdirectories, Product on the SKU pages but no AggregateRating despite hosting 30,000 verified reviews, and no LocalBusiness on 40 store-locator pages. Twelve schema-type errors are flagged in Search Console.
The audit produces one sprint of deletions (FAQPage, HowTo, two malformed WebSite blocks), one sprint of additions (LocalBusiness per location, AggregateRating wired into Product templates, Organization extended to subdirectories), and a quarterly cleanup of the errors. Three months in, rich product cards with stars appear on the relevant SERPs, the locations start surfacing in local pack queries, and the brand SERP shows a cleaned-up knowledge panel for the first time in a year. Nothing here is a moonshot. It is hygiene that pays.
The structured data spend that earns its keep
If schema gets one quarterly review and one engineering ticket, this is the place to spend them. The discipline most enterprise teams need is not learning a new schema type. It is the willingness to delete code that no longer renders and refresh the entity layer that has been on autopilot since 2019. A clean, deliberate schema layer is a force multiplier for everything else the SEO team ships, and it is one of the few technical investments that pays in both classic search and AI search. We design SEO programs to make that hygiene routine rather than heroic.
See where your brand stands in AI answers today, benchmarked against your competitors, no pitch required.

Your content can sit inside two billion AI answers a month and still send zero visitors
Your content can be quoted inside two billion AI answers a month and still send zero visitors. That is not a traffic problem, it is a measurement problem, and the old dashboard cannot see it.
read_post →
How to build video that AI search actually cites
YouTube is the most-cited source in Google's AI Overviews, and short-form is where product discovery now begins. What it takes to make your videos the ones AI search pulls from.
read_post →
Google turned every search into an AI answer first
Google rolled Gemini out as the default answer on every query worldwide, and the blue links slid below the fold. Here is what actually changed, and how to keep earning traffic when the answer arrives before the click.
read_post →