How to Measure AI Share of Voice for Your Brand.
// table_of_contents▸
- 1.What AI Share of Voice actually measures
- 2.Entity Share of Voice and Citation Share of Voice are different metrics
- 3.The formula and the discipline that protects it
- 4.How to measure it manually
- 5.Count quality, not just mentions
- 6.Let the AI define the competitive pool
- 7.What a useful number looks like
- 8.The failure modes that ruin the number
- 9.Tracking it without the sheet
- 10.Turning the number into work
AI answers do not have positions. Either the model names a brand or it does not. That single shift breaks the measurement habit enterprise SEO programs have built around rank tracking, and it leaves a question now landing in boardrooms with no confident answer: when a buyer opens ChatGPT and asks for a recommendation in a category, how often does the brand come up.
The number that answers the question is AI Share of Voice. It is the closest direct counterpart to the share of voice metric mature SEO programs already report on the classic SERP, redesigned for a surface that synthesises an answer instead of returning a list of links. It tells an enterprise team something rank tracking cannot tell it any longer, which is whether the brand is in the conversation when a model speaks at all, or invisible inside an answer the prospect never clicks away from.
This is the metric that earns a panel on the dashboard most enterprise SEO programs will rebuild over the next two quarters. The measurement discipline behind it is not technically complex. It is the part most programs skip on the way to buying a platform.
What AI Share of Voice actually measures
AI Share of Voice is the percentage of AI-generated answers, across a defined set of buyer prompts, that mention or recommend the brand relative to every other brand that surfaces.
Run two hundred prompt outputs across ChatGPT, Perplexity and Gemini and the brand appears in forty of them, and AI Share of Voice is twenty percent. The denominator is every answer that ran. The numerator is the answers where the brand made the cut. The shape is intentionally simple, because the underlying surface is. There is no "position three" to defend inside a synthesised answer. The model either names the brand or it does not.
The reason the metric earns its place in an enterprise reporting stack is downstream of the click economics. Pew Research's 2025 analysis of Google AI summaries found users clicked through to a source link on only 8 percent of visits where an AI summary appeared, compared with 15 percent on visits without one. The traffic answer has been migrating into the answer surface, and the only honest read of how a brand is performing inside that surface is whether the model names it at all.
Entity Share of Voice and Citation Share of Voice are different metrics
Before any measurement work begins, an enterprise team has to decide which version of AI Share of Voice it cares about. The two versions answer different questions and most programs need both, reported separately so they cannot be confused.
Entity AI Share of Voice counts how often a model names the brand as a recommendation, whether or not a URL is linked. "For maternal nutrition in Indonesia, brands like X and Y are well regarded". X got named. For most consumer and B2B categories this is the metric that maps to demand, because the model recommends the brand, the buyer reads the recommendation, and the next interaction is downstream of an answer the brand never appeared inside as a hyperlink.
Citation AI Share of Voice counts how often the brand's own content is cited as a source inside the answer. This is the metric that content briefs, schema implementation, and the entire owned-media program are working toward. Citation Share of Voice tells the team whether the pages it built are doing the persuading, or whether a third-party listicle is collecting the credit for the category the brand built.
| Metric | Question it answers | Best for |
|---|---|---|
| Entity SOV | Is AI recommending my brand at all? | Demand-led programs; categories where being named in the answer is the goal. |
| Citation SOV | Is AI using my content as the source? | Content-led programs; teams investing in owned media and structured pages. |
The formula and the discipline that protects it
The formula is the easy part.
AI Share of Voice (%) = (answers that mention your brand ÷ total answers in your prompt set) * 100
The denominator has to stay honest. It is every answer the team generated, including the answers where the brand was nowhere to be found. The temptation after a content push that lifted half the prompt set is to quietly retire the prompts where the brand still loses. Those are exactly the prompts the next sprint brief needs, not the prompts to remove.
How to measure it manually
Most enterprise teams will eventually move this measurement off a spreadsheet and into a dashboard. The manual discipline below runs before that move, not instead of it. A team that has never measured AI Share of Voice by hand will not know what its tool is actually measuring, and will not catch the silent assumptions when the number drifts in a quarter the work did not move it. The first month should be a sheet. The second and third should still be a sheet. By the fourth, the team has earned the right to automate it.
Block ninety minutes on the first Monday of the month. Five steps, repeated identically every cycle.
Lock the prompt set first. Twenty to thirty buyer prompts, chosen against actual demand and buying-stage coverage, frozen for the year. The prompt set is the measurement, so freezing it is what makes the trend meaningful. Drift in the prompt list is drift in the metric, and a metric that drifts cannot inform the work.
Run every prompt in a clean environment. Incognito windows, logged out, no chat history. AI models personalise heavily on past behaviour, and a logged-in account flatters the brand the team is measuring. The whole point is to see what a prospect with no history of interacting with the category sees.
Cover at least three engines. ChatGPT, Perplexity and Gemini at minimum, with Google AI Mode added for any category where the search behaviour triggers it. Results differ enough between engines that no single one is a proxy for the rest, and the cross-engine view is what protects the team from over-rotating on one platform's quirks.
Run each prompt several times. Outputs vary run to run on every engine. Three to five runs per prompt is the minimum sample size before any single result earns a place in the average. The repetition is the part that feels wasteful and is the part that distinguishes a measurement from an anecdote.
Log every result in one sheet. One row per prompt per engine per run, with three columns at minimum: brand mentioned (yes or no), brand content cited (yes or no, with URL), and every other brand that appeared in the answer. The percentage falls out of the sheet at the end.
The first month is a baseline, not a verdict. The value of the discipline lands in month two and three, when the team can see which prompts are moving and which are not, and the next brief writes itself off the gap.
Count quality, not just mentions
A passing mention buried in a list of eight is not the same kind of win as being named the primary recommendation. Counting both as a "1" collapses the most useful signal the measurement produces.
A 0 to 3 scoring rubric, applied to every mention as it gets logged, keeps that signal visible. Track the average score next to the raw percentage so neither metric stands alone.
| Score | What it means |
|---|---|
| 0 | Not mentioned at all. |
| 1 | Listed among other options, no detail. |
| 2 | Detailed mention with a specific strength or use case. |
| 3 | Positioned as the primary or default recommendation. |
A brand sitting at twenty-five percent AI Share of Voice with an average quality of 1.2 has a fundamentally different problem from a brand at twenty-five percent with an average of 2.6. The first is being tolerated in lists. The second is being recommended. The work the next brief should commission is different in each case, and the raw percentage will not tell the team which one it is looking at.
Let the AI define the competitive pool
The instinct of most enterprise teams is to pre-pick the competitor list before the measurement begins. Every brand the strategy deck already considers a rival, locked in before the first prompt runs. That instinct has to be resisted, because the most useful output of the entire exercise is the list of brands the model surfaces that the team did not expect to see.
The right approach is to let every brand that appears in any answer go into the tracking sheet. The models routinely surface direct rivals, partners, substitutes, adjacent categories, and at least one or two brands the strategy team forgot existed. That emergent competitive pool is often the highest-value finding of the first month, because it is the model's working definition of the category the brand actually competes in. The category as the model sees it is the category the buyer ends up shopping.
One refinement worth skipping is position-weighting brands by where they appear inside a synthesised answer. The order models return names in is close to random across runs on most prompts, and weighting by position dresses up noise as precision. Presence and quality are the only two signals stable enough to treat as measurement.
What a useful number looks like
There is no universal benchmark for AI Share of Voice, and any vendor that quotes one is guessing. The metric is meaningful relative to the brand's own previous reading and relative to the competitive pool the measurement itself produced.
Three reads carry the work. Against the competitive pool, where three named rivals each sitting at thirty percent against the brand's five percent is a visibility gap that demands a content response, not a measurement refinement. Against last month, where a move from eight percent to fourteen percent after a content push is the strongest evidence the work is landing that an AI search program will produce in its first year. By prompt class, where a strong number on informational prompts and a weak number on comparison prompts tells the team exactly where the next brief belongs.
The failure modes that ruin the number
The mistakes the discipline has to defend against are familiar from a decade of keyword-rank reporting. Measuring while logged in inflates the number and starts persuading the team of progress that the cold prospect never sees. Running each prompt once treats every answer as data when the underlying surface has run-to-run variance worth four or five samples per prompt. Tracking two hundred prompts produces a sheet the team abandons by month two, when twenty well-chosen prompts re-run consistently would have produced a real trend. Swapping the prompt set every month means measuring a moving target and never seeing whether any of the work moved the brand. Counting mentions without scoring quality treats a footnote and a top recommendation as the same outcome and hides the actual story.
The pattern beneath all five is the same pattern that has always broken SEO measurement at scale. Too much surface, not enough focus. The right move is fewer prompts, scored carefully, run on a schedule the team will not quietly drop.
Tracking it without the sheet
The manual method earns the team its understanding of what AI Share of Voice is and what moves it. Once that understanding exists, the spreadsheet stops being the right place to hold the measurement. StoryMint's AI Brand Performance tool is built around the same methodology and reports the same four numbers the manual method produces: share of voice across the locked prompt set, raw brand mentions, citation rate, and average position, each broken out by engine across ChatGPT, Gemini, Perplexity, Google AI Overview and Google AI Mode.
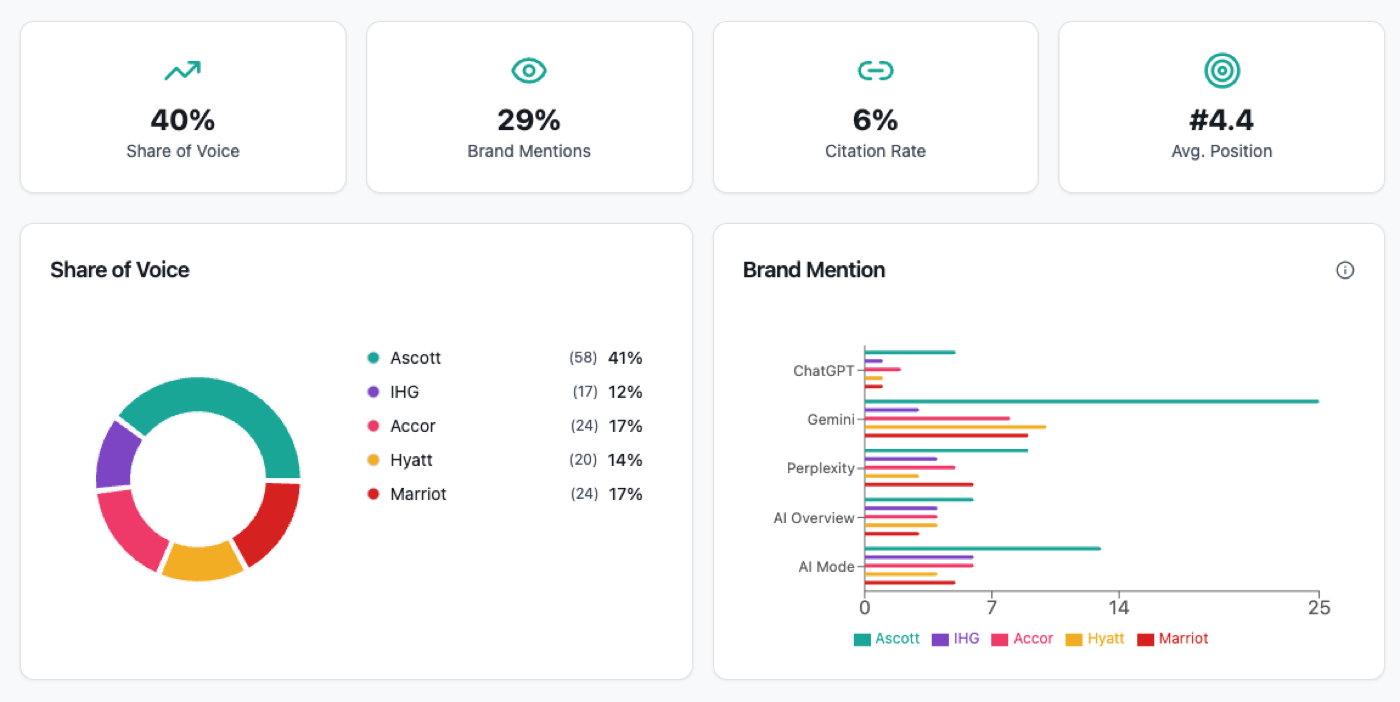
Source: StoryMint AI Brand Performance, sample view for a hospitality category run, May to June 2026.
The reason a tool starts to matter past the third or fourth month is not the math. It is the cadence. Twenty prompts across five engines at four runs each is four hundred manual queries a month that a single analyst can run, but then has no time to read. A dashboard preserves the discipline of the locked prompt set, the cross-engine view and the emergent competitive pool while removing the part of the work that does not produce judgement. The discipline stays. The repetition gets automated. The team gets its Monday back.
The hand-off matters in one specific way the procurement decision usually overlooks. Whatever tool the team adopts has to expose the underlying answers, not just the headline percentage. A score that the team cannot trace back to the prompts and the raw outputs that produced it is a score the team will not defend in a board meeting, no matter how clean the chart looks. StoryMint's reporting view keeps the manual logic visible underneath, which is the only reason a productised version of this measurement earns the trust the manual version built.
Turning the number into work
AI Share of Voice is a diagnostic. The point of the measurement is not the number itself, it is the next brief.
The prompts where the brand scores zero or one and a tracked competitor scores three are the content priorities for the quarter. The teardown is mechanical: pull the AI answer the competitor is winning on, find the page or pages the model is citing, study the structure, and out-execute it. Whatever the model is rewarding is visible in the citation, and the next brief writes itself off that observation.
The prompts where the brand already scores three are won. They earn defensive monitoring, not new investment. Moving budget away from prompts that are already won and into prompts where a competitor is winning is the single highest-leverage decision the metric produces.
The prompts where no brand scores above one are open category space. For a focused enterprise team with a genuine point of view, those are the prompts where one well-structured page can land in the AI citation pool inside a quarter. The team that measures AI Share of Voice consistently will find that pocket first, and the team that does not will read about a competitor finding it the quarter after.
If the program has never produced a baseline AI Share of Voice for the prompts that matter to the business, that baseline is what an AI search audit is designed to produce. The audit returns the competitive pool the model sees, the brand's current score across both entity and citation measurement, and the three prompts worth working on next. Teams that want to keep the measurement running after the baseline lands can move it straight into StoryMint's AI Brand Performance tool and inherit the same prompt set, the same engine coverage and the same scoring discipline on a dashboard. Most enterprise programs find at least one prompt on that first list they did not expect to be losing. The point of running the metric at all is to surface those prompts before the buyer does.
See where your brand stands in AI answers today, benchmarked against your competitors, no pitch required.

The technical work that decides whether AI search can use your pages
Most AI search advice skips the part that actually decides visibility, whether an answer engine can reach, render, and read your pages. This is that part.
read_post →
Your content can sit inside two billion AI answers a month and still send zero visitors
Your content can be quoted inside two billion AI answers a month and still send zero visitors. That is not a traffic problem, it is a measurement problem, and the old dashboard cannot see it.
read_post →
How to build video that AI search actually cites
YouTube is the most-cited source in Google's AI Overviews, and short-form is where product discovery now begins. What it takes to make your videos the ones AI search pulls from.
read_post →