Screaming Frog Finally Speaks Claude.

Earlier today, Screaming Frog rolled out SEO Spider version 24.0, and buried under the usual quality of life updates is the feature most of the SEO community has been quietly waiting for. A native Model Context Protocol (MCP) server. That means the crawler I have been driving with mouse clicks for over a decade can now be controlled with plain English from inside Claude, LM Studio, Cursor, or any other MCP-aware AI client.
I installed it on the day of release, connected it to both Claude Cowork and Claude Desktop, and ran a fresh crawl of search.agency through it. Below is the firsthand walkthrough, plus the four capability angles I think will reshape how technical SEO teams work day to day.
What MCP Actually Is, in One Paragraph
MCP is a protocol that lets AI assistants discover and call external tools. Once a server is registered, the assistant can list its capabilities, decide which to invoke, and feed the results back into your conversation. With Screaming Frog v24.0, the crawler itself becomes one of those tools. You ask Claude to run a crawl, and Claude tells the SEO Spider to do it, then reads the output back to you. No CLI flags, no exports, no spreadsheets in between.
Setting It Up: My Walkthrough
Here is exactly what I did on a Mac. The Windows and Linux paths are similar.
Step 1. Update Screaming Frog to version 24.0. Open the SEO Spider, go to Help and check for updates. If you are on anything below 24.0, the MCP option will not exist. Fresh installers for Windows, macOS Apple Silicon, macOS Intel, and the various Linux flavours are all on the Screaming Frog download page.
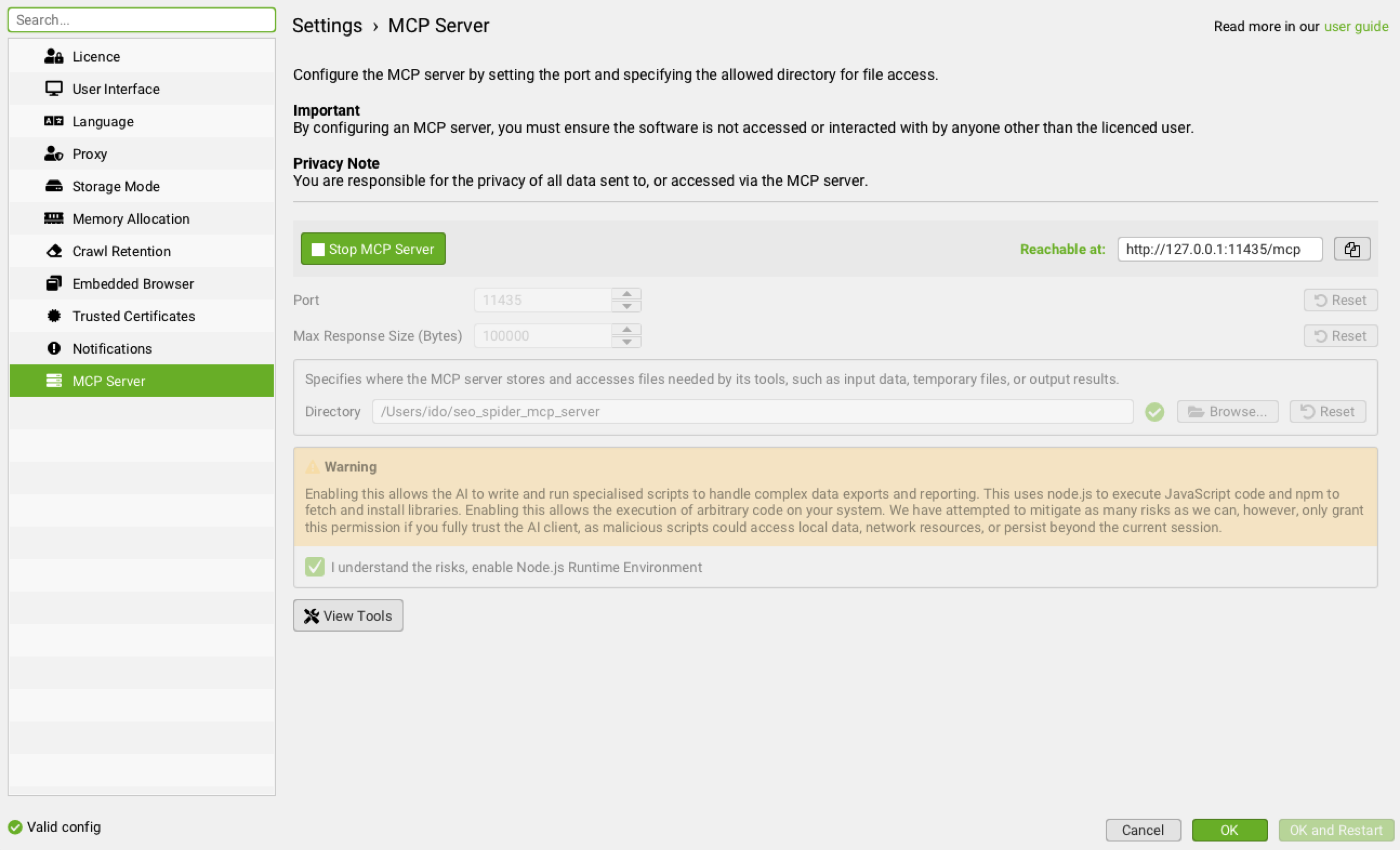
Step 2. Enable the MCP server inside Screaming Frog. The full settings live in the official MCP server documentation. In short, you give the server a base directory it is allowed to read and write inside. Mine is set to `/Users/***/seo_spider_mcp_server`. Every export, screenshot, or generated script the assistant produces will land in that folder. Keep it scoped. Do not point it at your home directory.
Step 3. Register the server in your AI client. This is where Claude Cowork and Claude Desktop diverge slightly.
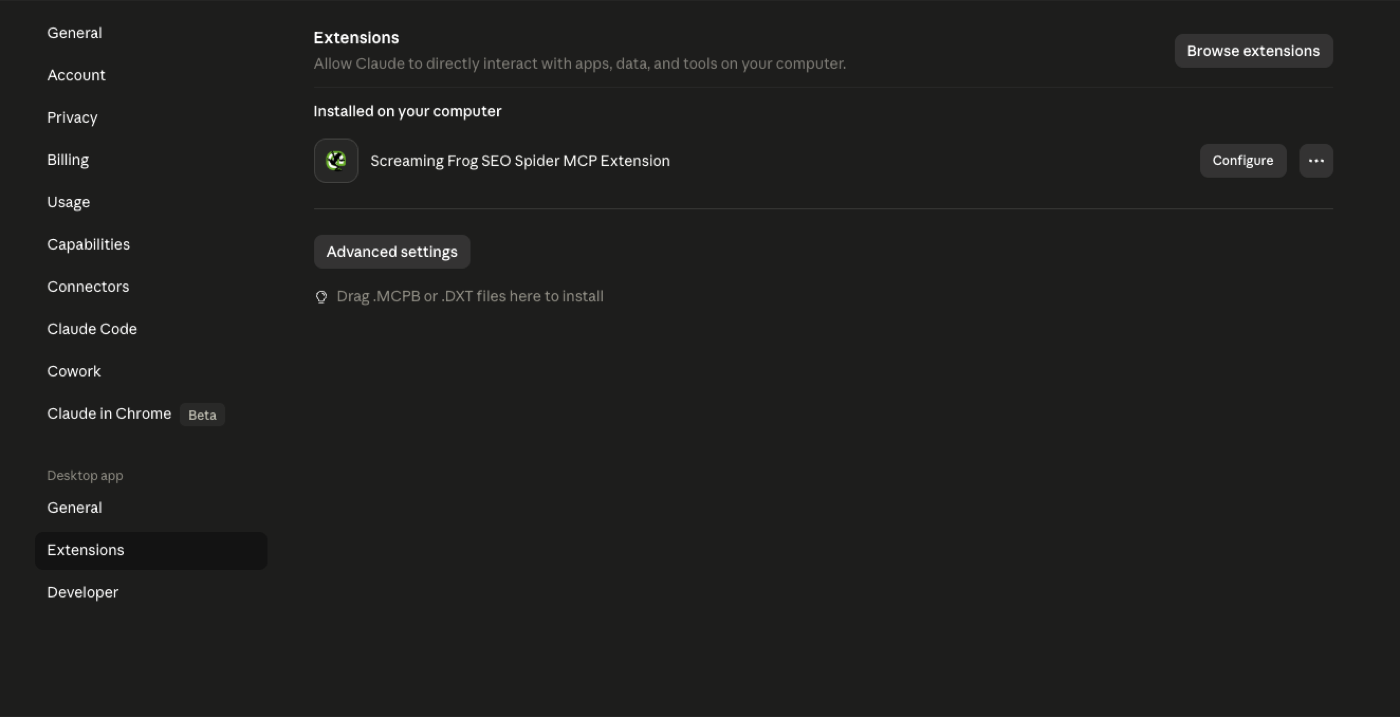
For Claude Cowork, open settings, find the Extensions panel, and add the Screaming Frog SEO Spider MCP extension. Cowork handles the connection wiring for you. After the green light, type something simple like list my recent crawls in chat. If Claude lists them, you are connected.
For Claude Desktop, you edit the `claude_desktop_config.json` file and add the Screaming Frog MCP entry by hand. The exact server command and arguments are in the Screaming Frog docs above. Restart the app once, and the new tools appear in the lower toolbar.
Step 4. Smoke test it. I asked Claude to call `sf_list_allowed_base_directory` and then `sf_list_crawls`. Within five seconds it confirmed the base path and pulled my last five projects, including the search.agency crawl from version 23.3 in April and the version 24.0 crawl from this evening. That is when it clicked. The crawler was no longer a separate app I tab into. It was just another voice in the conversation.
What It Actually Unlocks
I tested four angles. Each one matters for a different reason.
1. Crawl and Audit Basics, Without Touching the UI
The simplest, and the first thing you should try, is letting Claude run a crawl end to end. Crawl search.agency, then summarise the top issues. What used to require opening the app, configuring spider settings, waiting, then clicking through the Overview tab now happens in one prompt. Claude can call `sf_crawl`, poll `sf_crawl_progress`, and once complete, pull from the full library of built-in reports. The available report list is enormous. Crawl Overview, Issues Overview, Hreflang validation, PageSpeed opportunities, Structured Data errors, Accessibility violations, Cookie summaries, and dozens more.
For weekly recurring audits, this collapses a half hour of clicking into a single sentence.
2. AI-Powered Analysis Layered On Top
The crawl is just raw data. The point of running it through Claude is what comes after.
Once the data is in the conversation, Claude can prioritise issues by impact, group similar problems together, and write the actual remediation tickets. I tested a prompt along the lines of take the latest search.agency crawl, identify the three most damaging technical issues, and draft a ticket for each in Jira format. The output was useful enough to send to a developer without much rewriting. That is the real shift. The audit and the action plan now happen in the same window.
3. Content and Embeddings Work
This is the angle that surprised me most. Screaming Frog v24.0 exposes the bulk page content export and the embeddings export through MCP. That means you can ask Claude to pull the body content of every URL in a crawl, generate embeddings, and cluster the pages by semantic similarity. In one workflow. Without writing a line of Python.
For content teams, this is a serious shortcut. You can spot near-duplicate articles competing for the same query, find cannibalisation across your blog, or map out which old pieces should be consolidated. The kind of work that used to require a custom script and an afternoon now fits inside a Claude conversation.
4. Real Agency Workflows
The four use cases I am already moving into production at Search Agency:
A weekly client health check that runs the crawl, compares it against last week, and outputs a one-page summary with the deltas highlighted. A competitor teardown where Claude crawls a competitor site, exports key on-page elements, and side-by-sides them against the client. A pre-launch QA pass that crawls a staging environment and flags any new redirects, broken links, or missing tags before they hit production. An internal linking audit that pulls the link graph, runs Claude analysis on link equity flow, and recommends specific new internal links to add.
None of these are theoretical. I am running variations of all four this week.
What It Does Not Do, Yet
A few caveats worth setting expectations on.
Not every Screaming Frog feature is wired up through MCP today. Screaming Frog has said the surface area will expand based on user feedback, so the first few months will reward people who file requests for the specific commands they want exposed. The MCP also depends on the SEO Spider being open and running on your machine. This is not cloud-hosted. If you close the app, the tools go offline. And finally, the larger the crawl, the more careful you should be about which exports you ask Claude to load into context. Pulling the full content of 10,000 pages into a chat is not the right move.
For SEO teams, this update changes the gradient of the work. The technical audit moves from a sequence of clicks into a conversation. The reporting moves from a deck of screenshots into a live discussion with someone who has already read the data. The competitor analysis, the content cluster, the link audit, all of it shifts from a multi-day project into something you can finish over coffee.
Screaming Frog has been the workhorse of technical SEO for years. Wiring it directly into an AI assistant turns it into something closer to a thinking partner. If you have not updated yet, do it today, point Claude at it, and see how much of your usual workflow disappears.
Resources
See where your brand stands in AI answers today, benchmarked against your competitors, no pitch required.

Most of what AI cites about your brand lives on sites you do not control
The first Total Graph Authority post named third-party validation as the layer AI cites most. This is the deep dive, six trust tiers, engine by engine, in the order to build them.
read_post →
The five graphs an AI assistant reads before it decides to cite you
Backlinks are one connection an AI model follows. Here are the other four graphs that decide whether you get named in the answer.
read_post →
What AI knows about your brand is decided first on your own domain
Third-party mentions and social clips only corroborate a story your own site has to tell first. Here is how to build the first-party layer AI reads before it trusts anyone else.
read_post →