What It Takes to Make Your Website Agent-Ready in 2026.
// table_of_contents▸
- 1.What "agent-ready" actually means
- 2.Discoverability, which is mostly SEO you already know
- 3.Content accessibility, or serving the page an agent wants
- 4.Bot access control, the governance layer
- 5.Capabilities, where reading turns into doing
- 6.Commerce, the layer with real money and a standards war
- 7.What matters now, and what is still theater
The web was built for human eyes. An AI agent reads it differently. It parses the underlying structure rather than skimming the layout, and it wants a clean, machine-readable list more than a category page to look at. It also does more than read now, filling carts and paying on behalf of a person who never visits your site at all.
On 17 April 2026, Cloudflare put a number on how prepared your site is for that shift. The Agent Readiness Score is a public scanner, live at isitagentready.com, that grades any URL from 0 to 100 across sixteen checks. Most sites score low today, and that is fine for the moment. The reason to pay attention is the direction of travel, not this quarter's number.
What "agent-ready" actually means
Strip away the standards and an agent needs three things from your site. It has to find you, read you cleanly, and act with you, which on a commercial site means buy from you. Cloudflare's scanner sorts its checks into five layers that map onto those needs, and the layers are a better way to think about the work than the individual badges.
| Layer | What it answers for an agent | Example standards | Where it stands |
|---|---|---|---|
| Discoverability | Can an agent find your content and entry points | robots.txt, sitemap, Link headers, DNS-AID | Mostly do-now, classic SEO plus extensions |
| Content accessibility | Can an agent read your content without fighting the page | Markdown negotiation, llms.txt | Emerging, low cost to try |
| Bot access control | Can you state which agents may use what, and prove who is who | AI bot rules, Content Signals, Web Bot Auth | Do-now policy work |
| Capabilities | Can an agent take actions, beyond reading | MCP Server Card, WebMCP, Agent Skills, OAuth discovery | For sites with real actions or APIs |
| Commerce | Can an agent buy from you | ACP, UCP, x402, MPP | For transactional and retail sites |
Discoverability, which is mostly SEO you already know
The first layer is the most familiar. A clean `robots.txt`, a real `sitemap.xml`, and proper RFC 8288 Link headers are the same hygiene that has fed search crawlers for two decades, now read by a new kind of client. If your technical SEO is in order, you pass most of this already.
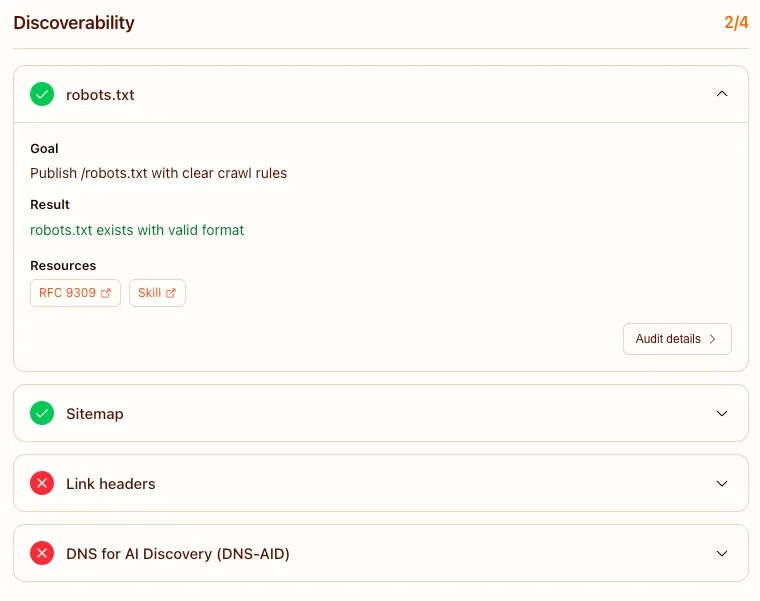
The one new entry is DNS for AI Discovery, or DNS-AID, which uses DNS records to point an agent at your machine-readable entry points before it even fetches a page. It is early and barely adopted. The takeaway is that discoverability has not been reinvented, it has been extended, and the cost of doing the classic parts well is near zero because you should be doing them anyway.
Content accessibility, or serving the page an agent wants
An agent does not want your hero animation, your cookie banner, or your nav. It wants the content. Markdown content negotiation lets your server hand an agent a clean Markdown version of a page when it asks for one, stripped of the interface a human needs (Cloudflare). The related idea, an `llms.txt` file, offers a curated map of your most important content so a model does not have to reconstruct your site from scratch.
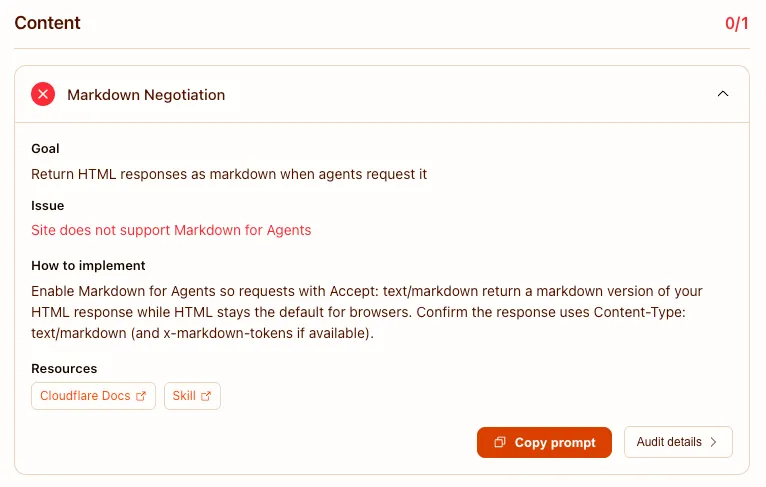
Both are cheap to try and neither is settled. The deeper point sits underneath them. An agent can only use content it can extract, which is the same reason client-rendered pages read as blank to most AI crawlers. Serving clean, server-rendered content is the foundation that every one of these formats is dressing up.
Bot access control, the governance layer
This is the layer most teams underweight, and it is do-now. AI bot rules in `robots.txt` let you say which crawlers may touch what. Cloudflare's Content Signals go further and let you express how your content may be used once fetched, whether for search, for AI input, or for training, which is a different question from whether a bot may access it at all. Web Bot Auth adds cryptographic identity so a well-behaved agent can prove it is what it claims, which is what makes selective access possible instead of a blanket allow or block.
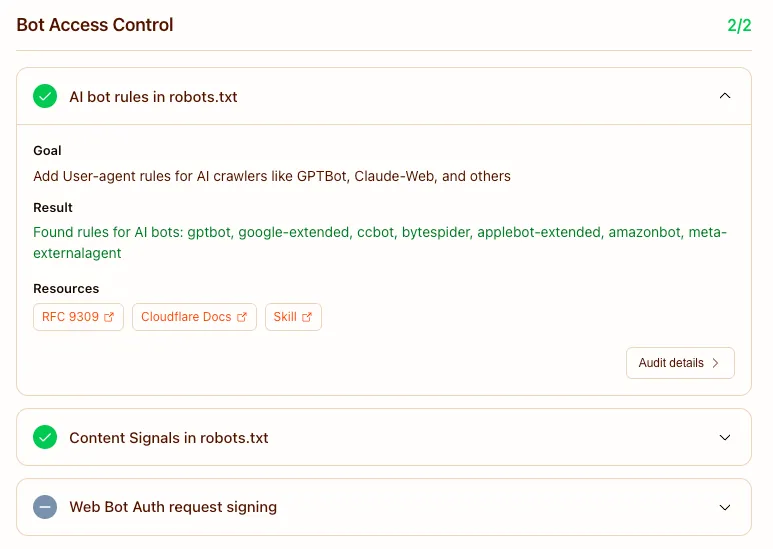
Getting this layer right is how you stay in the answer while keeping control of the terms. We have written before about reading your server logs to decide which AI crawlers earn their bandwidth, and this is the enforcement side of that same decision.
Capabilities, where reading turns into doing
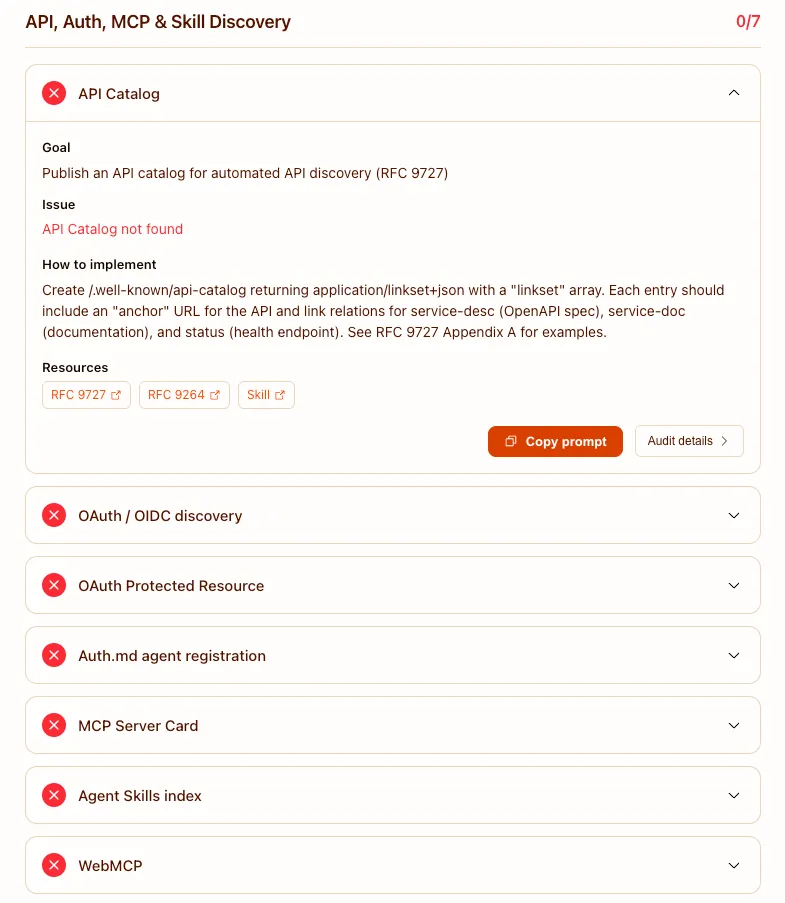
Here the web stops being a library and starts being a set of tools. The Model Context Protocol, MCP, lets an agent call your functions rather than scrape your pages, and an MCP Server Card is how it discovers that those functions exist. WebMCP brings the same idea into the browser, exposing a page's actions to an in-browser agent. Agent Skills package reusable capabilities, and OAuth discovery plus the Protected Resource standard (RFC 9728) handle the part nobody can skip, letting an agent authenticate before it acts.
This layer is not for everyone yet. A content site has little to expose here. A SaaS product, a booking platform, or anything with a real API has a genuine reason to start, because an agent that can call your booking endpoint is worth more than one that can only read your availability page. For most brands this is the layer to understand now and pilot later.
Commerce, the layer with real money and a standards war
The last layer is the one moving fastest, because the payoff is direct. Several protocols are competing to define how an agent buys, and they are not interchangeable.
The Agentic Commerce Protocol, ACP, comes from OpenAI and Stripe and powers Instant Checkout inside ChatGPT, defining how an agent discovers a product, builds a cart, and checks out. Google's Universal Commerce Protocol, UCP, launched in January 2026 with Shopify and a roster of major retailers and powers checkout in Google AI Mode and Gemini, covering a wider lifecycle including post-purchase. Coinbase's x402 revives the dormant HTTP 402 status code so an agent can pay for a single resource or API call directly, often in stablecoins, with no human in the loop. MPP sits alongside these as another payments rail.
If you sell things, this is the layer to watch closely and choose deliberately, because backing the wrong protocol or none is how you get left out of the checkout that happens inside someone else's assistant. If you do not sell online, you can read this layer as a forecast and move on.
What matters now, and what is still theater
A 0-to-100 score invites you to chase 100, and that is the trap. Most of these sixteen checks are nascent, several will not survive contact with the market, and a perfect score on standards nobody has adopted buys you nothing.
The work that pays off today is narrow and unglamorous. Get your `robots.txt`, sitemap, and AI bot rules correct, decide your content-use policy with Content Signals, and serve clean server-rendered HTML that an agent can actually extract. That alone moves your score and, more importantly, makes you legible to the crawlers already feeding AI answers. The capability and commerce layers are worth a real pilot only if you have actions or products an agent would transact against. Everything else, DNS-AID, WebMCP, agent-to-agent discovery, is worth understanding and not worth a sprint.
None of this is a separate discipline. Being found by people was SEO. Being cited by AI answers is the work we describe as GEO and AEO. Being usable by agents is the next layer up, and it rewards the same fundamentals every time, content a machine can reach, read, and trust. The brands already building their sites for software to operate, and not only for people to read, will be the ones the next wave of agents can use.
See where your brand stands in AI answers today, benchmarked against your competitors, no pitch required.

The five graphs an AI assistant reads before it decides to cite you
Backlinks are one connection an AI model follows. Here are the other four graphs that decide whether you get named in the answer.
read_post →
What AI knows about your brand is decided first on your own domain
Third-party mentions and social clips only corroborate a story your own site has to tell first. Here is how to build the first-party layer AI reads before it trusts anyone else.
read_post →
75% of What AI Mode Cites in Travel Is Guide Content
Google AI Mode cites about 26 sources to answer a single travel query, and three quarters of them are the guides, tips and itineraries most teams are cutting. Our 100-query study on what it pulls, who gets cited, and why the click drop isn't a content-quality drop.
read_post →