We Ran Our Own Page Through an E-E-A-T Auditor and Scored 61.
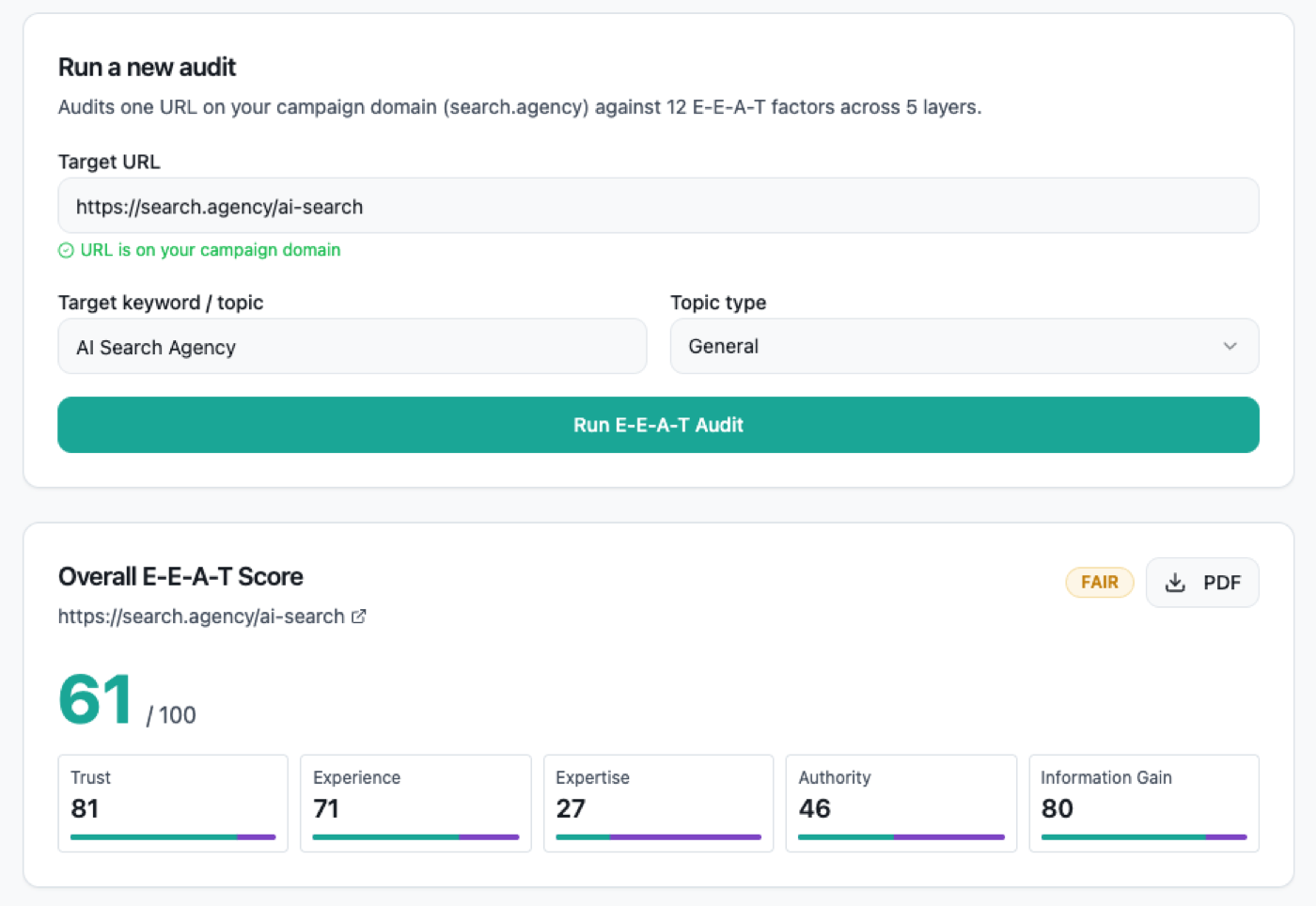
We ran the page we use to sell AI search work, search.agency/ai-search, through StoryMint's E-E-A-T Auditor, and it came back with a 61 out of 100. Fair, not good. E-E-A-T is Google's shorthand for Experience, Expertise, Authoritativeness, and Trust. Those are the qualities human reviewers, and increasingly Google's own ranking systems, weigh when judging whether a page deserves to rank and get cited. The auditor scores a single URL across all five layers built on that framework, each one broken into weighted factors marked from zero to ten against signals a machine can actually verify. Our page landed at Trust 81, Information Gain 80, Experience 71, Authority 46, and Expertise at just 27. Publishing that number is the point. The clearest way to show what an audit like this catches is to run it on the page we are most invested in looking good, then fix it in public.
| E-E-A-T layer | Score / 100 | Read |
|---|---|---|
| Trust | 81 | Strong |
| Information Gain | 80 | Strong |
| Experience | 71 | Fair |
| Authority | 46 | Weak |
| Expertise | 27 | Failing |
| Overall | 61 | Fair |
Why audit the page you least want to fail
The reason to point the tool at your own flagship page is that it is exactly where the gap between what you claim and what a machine can confirm is widest. A sales page is written to persuade a human. It reads well, it sounds authoritative, it closes. None of that tells an AI engine anything it can act on. Search systems do not grade tone. They look for structured, checkable evidence that the experience and expertise on the page are real. The 61 is the distance between how the page reads and how it computes. Every site has that gap. Most teams never measure it because they are reading their own page the way a customer would, not the way a crawler does.
What the page got right
Trust and Information Gain carried the score. Trust, at 81, rested on the boring fundamentals: HTTPS with a valid certificate, and a full set of contact details with email, phone, and a physical address all present, each scoring a perfect ten. Information Gain, at 80, came from something rarer. The auditor rewarded the page for standing apart from competitors, specifically for sending readers to the published framework behind the work rather than guarding it as proprietary. That layer measures originality of substance, not just of wording, and a page that shows its method openly scores well on it.
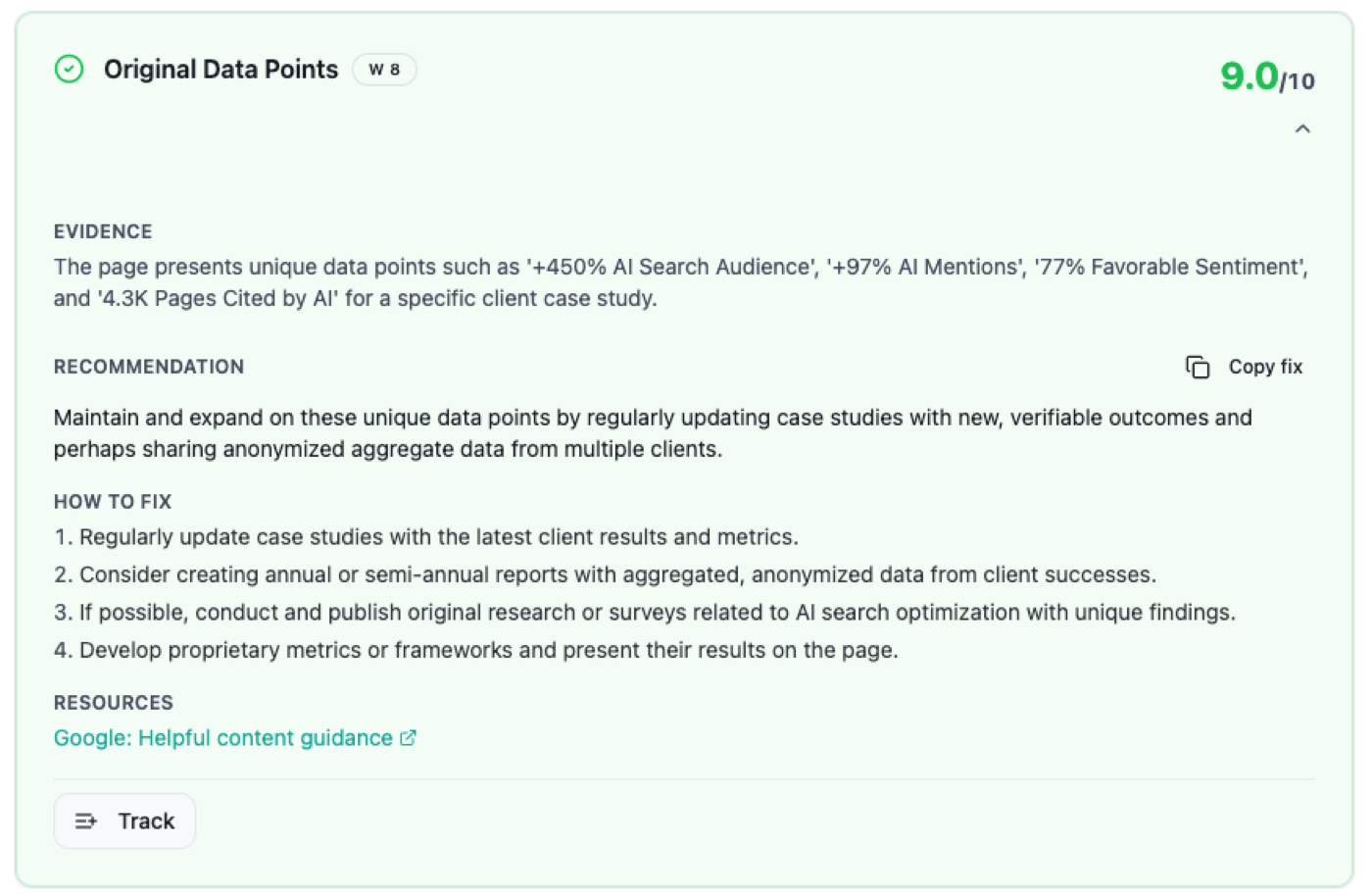
The page banks a strong Experience signal from the same instinct: the hard client numbers it carries, a 450 percent lift in AI search audience, a 97 percent rise in AI mentions, 77 percent favorable sentiment, and 4,300 pages cited by AI, all tied to a named case study, were read as genuine original data and scored a 9. The lesson for any site is unglamorous but freeing: original numbers, an open method, and clean trust signals are not the hard part of E-E-A-T. Most decent pages can clear them. The score is lost somewhere else.
Where it fell apart, and why it is the most common failure
Expertise at 27 is the layer that sank the score, and the reason is the single most widespread blind spot in SEO content. The page states its expertise confidently in prose. It mentions the team that wrote the playbook, the kind of first-person line that actually helped its Experience score. But the machine-readable proof of who that team is barely exists. The page carries no Person or Organization schema at all, the factor that scored a 1. Without schema there are no sameAs links pointing to LinkedIn, Crunchbase, or any profile an engine could follow to confirm who stands behind the claims, which is why sameAs link health scored a 2. And only one verified mention of the brand turned up on a high-authority site, leaving the external footprint at a 5. This is the heart of it. An AI engine deciding whether to trust a source does not read "the team that wrote the playbook" and feel reassured. It looks for schema.org Person and Organization markup, sameAs links it can follow to known profiles, and a footprint of mentions on sites it already trusts. We had written the expertise into the copy and forgotten to encode it where it counts.
Experience, at 71, was not a failure, but its weakest factor pointed the same way. The page uses two images, and while neither was a stock photo, neither carried any EXIF metadata either, which capped visual originality at a 5. Original photos and screenshots carry data that signals first-hand experience; stripped or generic images carry none. It is a smaller signal than schema, but it is the same mistake in miniature: real experience left invisible to a machine because nobody encoded it in a form the machine reads.
The authority gap no markup can close
Authority came in at 46, and it split cleanly into one thing the page has earned and one thing it has not. It has a healthy niche footprint, eight verified community references to Search Agency across places like Reddit, GitHub, and Medium, which scored a full 10. What it lacks is a citation in Google's AI Overview for its target term, which scored a 1, for a reason the auditor named plainly: the domain does not rank in the top ten for the term, and AI Overview citations overwhelmingly go to pages already ranking in the top few organic results. This is the part no amount of schema can fix. Getting cited in an AI answer is downstream of organic ranking, which is downstream of the slow work of [authority and relevance](/seo). It is worth being honest that the single highest-weighted factor in the whole audit is the one we cannot shortcut.
The fix list, in the order the weights demand
A teardown is only useful if it ends in a ranked list, and because the auditor weights every factor, the order is not a matter of opinion. Three moves do most of the work.
First, ship Author and Organization schema. It is the fastest high-value win available: one block of JSON-LD with Person and Organization markup, the knowsAbout, worksFor, and sameAs fields filled with real profiles, moves the worst factor in the worst layer, and validating it in Google's Rich Results Test closes the sameAs problem in the same pass.
Second, encode the experience that already exists. Swap the metadata-stripped images for original screenshots and diagrams that keep their EXIF, and push the first-person language further by naming methods, results, and people instead of gesturing at them.
Third, keep grinding the ranking, because the citation follows it. The AI Overview factor carries the heaviest weight in the audit and will not move until the page ranks in the top few for its term. That is organic authority work, not a markup task, and it is the long pole that everything else waits on.
Beyond those three, the smaller lifts are obvious once the audit names them: add the transparency pages it flagged, an editorial policy and a clear privacy and terms page, and earn a few more high-authority mentions to thicken the external footprint. None of it is exotic. All of it is the difference between a page that says it is credible and a page a search engine can confirm is.
Run the same audit on your own page
The reason we ran this on ourselves and published the number is that the gap we found is not unique to us. Almost every page looks more authoritative to a person than it proves to a machine, and the only way to see the difference is to measure it. StoryMint's E-E-A-T Auditor scores any URL the same way it scored ours, across the same five layers and every factor under them, and hands back the same ranked, weighted fix list. You can run it on your own page in a few minutes and see exactly where your expertise, authority, and trust are real but invisible. We will re-run our own audit as we ship the fixes and publish the new score, because a teardown you never revisit is just a confession.
See where your brand stands in AI answers today, benchmarked against your competitors, no pitch required.

How to build video that AI search actually cites
YouTube is the most-cited source in Google's AI Overviews, and short-form is where product discovery now begins. What it takes to make your videos the ones AI search pulls from.
read_post →
In Google's AI Mode, the source getting cited most is Google itself
A study of 50,000 commercial keywords found Google has become the second most-cited source inside its own AI Mode, by pulling from its own Business Profiles and Knowledge Panels. That rewrites the local SEO playbook.
read_post →
A peer-reviewed study just measured what ChatGPT is doing to Google search
Bocconi University tied broader ChatGPT access to a 9.4% drop in traditional search, climbing to 17% after twenty weeks. The headline is real, but the detail underneath it is where the strategy sits.
read_post →